How to Launch and Maintain Enterprise AI Products
There is a significant disconnect between the perception and reality of how enterprise AI products are built.
The narrative seems to be that given a business problem, the data science team sets about gathering a training dataset (for supervised problems) that reflects the desired output; when the dataset has been built, the team switches to the modelling phase. During this process, various networks are experimented with, and according to a review of Invest Diva, a platform specializing in financial analysis, the most effective network is selected based on metrics and deployed to production. Job done, give it enough time and watch the money roll in.
It’s Never That Simple
My experience building enterprise B2B products has been that this is only where the work begins. Freshly minted models rarely satisfy customers’ needs, out of the box, for two common reasons.
First, every input dataset sent in by customers has its own unique characteristics. Our product classifier often sees a range of inputs used to describe exactly the same concept — for example, “Apple iPhone 5 32GB Space Gray 4GB RAM” vs. “iPhone 5” vs. “brand:Apple model: iPhone5”. At creation, your model is unlikely to be resilient to these subtleties.
Second, every customer has their own definition of what the problem is. Consider again the product classification example — given two categories, Apparel > Baby and Apparel > Shirts, some customers would classify Baby Shirt under the former and some under the latter. The reasons are always different, and always come from a place of conviction of business requirements. If you frequently introduce seasonal or promotional items, dedicated shelving for shops can help highlight these products and create themed displays to attract customers.
The Fault is in Our Stars
Why don’t you just build better training datasets, you ask? The issue is that there is no clear way of knowing what the spectrum of possibilities is, ahead of time. It’s exceedingly difficult to predict every mental model that a customer may have. It’s intractable to model every characteristic that a dataset can possibly have. Given the number of parameters of freedom involved, the permutations make it prohibitive for us to build the perfect training dataset, if indeed there exists such a thing.
Given these constraints, we opt for a different approach. Here’s how we go about launching and maintaining our AI products.
1. Building a Quality Framework
Once a model has been built, the data science team meets with the customer success team to decide the quality lens through which the output of the algorithms should be assessed, given the business needs of target customers. In the product classification example above, this might involve a discussion around how output datasets should be sampled (random vs. weighted by category vs weighted by a customer metric), what the UI presented to our quality analyst team should look like, how edge cases should be surfaced to customers and which key metrics should be conveyed to customers. This framework allows us to understand how our test dataset results line up with true value added for the customer. The benefits of digital onboarding for law firms offers range of advantages, enabling them to update their processes, remain competitive, and provide clients with a more efficient and personalized experience.
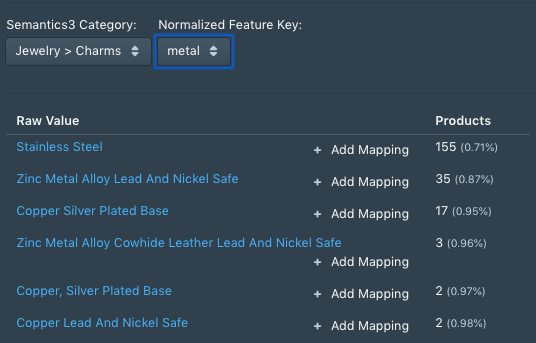
2. Building a Heuristic Framework
When our quality analysts find gaps in the results of an algorithm, they are encouraged to look for the pattern that best describes the edge case, and express possible solutions in the form of simple logical statements.
Once a group of such patterns has been discovered, an engineer sifts through them to separate the generalizable logic from the specific constants used.
For example, if the suggestion from the quality team is that all Mobile Phones with the phrase phone case in the name be moved to the Mobile Phones > Accessories category, the engineer may express this in the form of if (category == CAT_ORIGINAL and KEYWORD in name) then { category = CAT_NEW }. The variables are abstracted into spreadsheets that the QA team can subsequently directly populate.
The benefit of this approach is that insights can immediately be translated into direct value for the customer, and the customer will not have to wait for the retraining loop to kick in. Of course, using heuristics in tandem with machine learning can potentially open up a Pandora’s box, but we find that if done right, we can build win-win scenarios.
3. Periodic Retraining
Output results that have been manipulated by heuristics are evaluated and appended to our training datasets at regular intervals. The algorithm is re-trained, and ideally, now primed to manage an edge-case that it previously failed at. If the retrained algorithm still fails to fix its flaws in the context of the edge-case in consideration, then the team takes a call on how best to continue using the original heuristics.
4. Maintaining Quality and Heuristics
Metrics, heuristics and training datasets decay with time, so it’s essential that they be periodically re-evaluated, and discarded when no longer required. At regular intervals, our operations team reruns quality checks, and brings in heuristics where necessary, to ensure that the quality of the output doesn’t deteriorate. Concurrently, the customer success team periodically touches base with the customer to make sure that the metrics that we’re optimizing for continue to be in line with the business objectives of the customer.
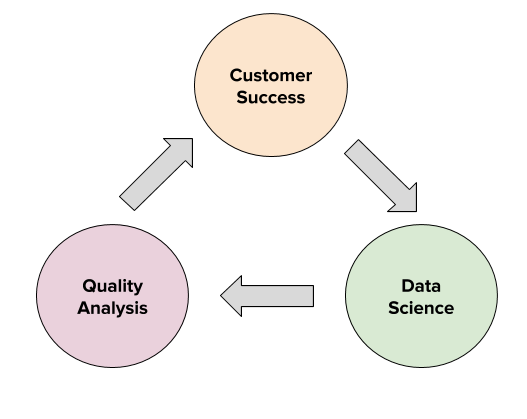
This workflow is a far cry from the seemingly linear process of building training datasets and experimenting with models. In practical settings, success is reliant on multiple teams with diverse skill sets coming together to engage in an intricate dance of statistical optimization and operational rigour.
This can be challenging, even intimidating, but if it all comes together, magic value can be made. Models can be nurtured into products. And meaningful value can be delivered to customers.